
We provide AI and ML development services. We have a team of experts who can design and develop large language models to delivery smart solutions. We train them on the latest data to make sure that they can deliver quality output in different conditions. With our AI and ML services, you can automate task and cut cost for your company










As a leading AI and ML Development company, we have a team of engineers experts in delivering high-quality solutions. We provide end-to-end services, so you don’t have to worry about anything. Also, with our expertise and experience in different industries, we help you solve industry-specific challenges with our AI and ML solutions.
Our AI consulting services combine our extensive domain and industry knowledge with AI technology and an experienced-led methodology that enhances,…
AI is changing how business operate and we provide custom AI solutions based on your unique business requirements. At Tuvoc,…
Easily analyze data for your business with our Computer Vision softwareDevelopment Services. Our team is expert in developing algorithms to…
Our NLP services help businesses build automated solutions for providing better experience. Our experts can help you analyze customer feedback…
Plannnig to build an AI and ML solution? Our team can help. We have a team of experts who can…
At Tuvoc, we are experts in using generative AI to help businesses generate content faster. Our team can create tools…
Planning to build your own LLM? We provide custom LLM development services to help you. Our services are customized based…
At Tuvoc, we are experts in developing adaptive AI solutions. We create AI systems that can learn and adapt. We…
We are experts in building machine learning models for your business. We build custom ML solutions to fit your exact…
We are experts in providing consulting for your ML development services. Our team copmes from different industry backgrounds. They have…
Our deep learning model development services help you tap into advanced AI. Our team is expert in designing and developing…
We are experts in providing ML development services. We help businesses solve their business challenges with our custom solutions. At…
Validate your ideas before launch with our MVP development services. Our team is expert in building MVP with core features,…

We offer a range of AI and ML services. Whether you are a startup or an enterprise, you can choose from our services. We customize them for all our clients, so you get a high quality product.

We don’t want you to settle for less. Every app we develop is customized to your users and hence gets you the intended results.
Blending success through cutting-edge technological endeavors

Bubble

WordPress

Shopify

Magento

Drupal

Node.js

PHP

Laravel

CakePHP

Codelgniter

Java

Python

.NET

Angular js

ReactJS

Vue JS

TypeScript

WPF

HTML

ios

Android
React Native

Flutter

Ionic

Xamarin

AWS

Google Cloud

Azure

Jenkins

Selenium

MySQL

DynamoDB

PostgreSQL

Oracle

Firebase

MongoDB

Redis
Angular
HTML

ReactJS
TypeScript
Vue JS
WPF
Android
Flutter
Ionic
ios
Xamarin
CakePHP
Codelgniter
Java
Laravel
Node
PHP
Python
AWS
Azure
GCP
Jenkins
Selenium
Embark on a journey of success with our comprehensive case studies. Explore real-world examples of challenges overcome and victories achieved, offering valuable insights for strategic decision-making.
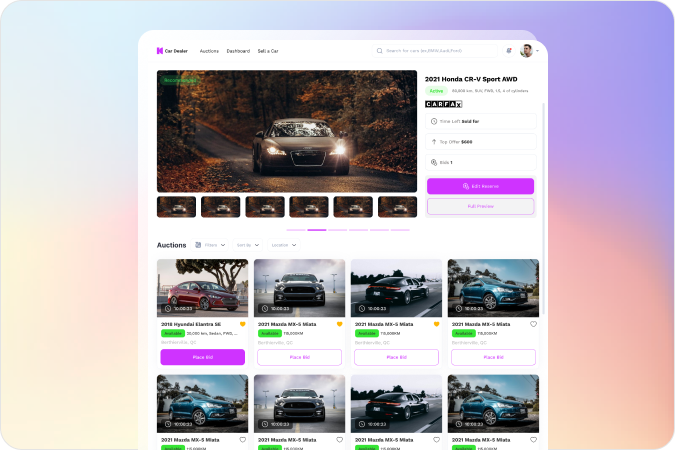
Autonerd is a cutting-edge Bubble App crafted to simplify the vehicle buying and selling process for car dealerships...

EMFI Securities Limited is a main provider of financial services, taking special care of corporate, institutional, and abundance the board...
As a Top Web Development Company in India, we make sure your solution works successfully with easy to use and is attractively performed by users.

Healthcare

Financial

Hospitality

Education

Information Technology

Marketing Communication

Travel

Legal

Manufacturing

Fitness
Healthcare
Financial
Hospitality
Education
Information Technology
Marketing Communication
Travel
Legal
Manufacturing
Fitness
Client Success Stories: Empowering Journeys, Amplifying Experiences
Stay updated with the latest happenings in the world of emerging technologies.

Introduction Over three million developers have deployed 4.69 million applications worldwide, enabling businesses to enhance MVP development and launch it…

Note: The estimated cost of hiring Python developers can range between $ 15-17 hourly or more. The exact cost, team…

Introduction Python is among the popular programming languages due to its comprehensive libraries, frameworks, and versatility. Many popular companies like…

Thank you for getting in touch! Kindly fill the form, have a great day!




