
How to Build a Custom RTB Platform | Architecture, Cost & Timeline

Manoj Donga
AdTech
Published : Feb 20, 2026

Key Takeaways
- Scale Requirement: You need massive monthly ad spend to justify the fixed engineering costs of building.
- Control Factor: Owning the source code allows for custom bidding algorithms that DSPs cannot support.
- Margin Recovery: Eliminating the standard 20% tech fee pays for the server infrastructure over time.
- Maintenance Reality: The ongoing cost of latency management and server upkeep often surprises new teams.
When Does It Make Sense to Build Your Own RTB Platform
Most companies burn money building this. It is a vanity project 90% of the time. You should only build RTB platform infrastructure if the tech fees exceed the engineer salaries. That is the only math that matters. If you spend under $50k a month, just use a white-label solution.
RTB platform development is painful. You are building a high-frequency trading desk. The latency requirements are brutal. If you cannot handle 100k QPS without crashing, do not start. The server costs alone will kill the margin before you bid.
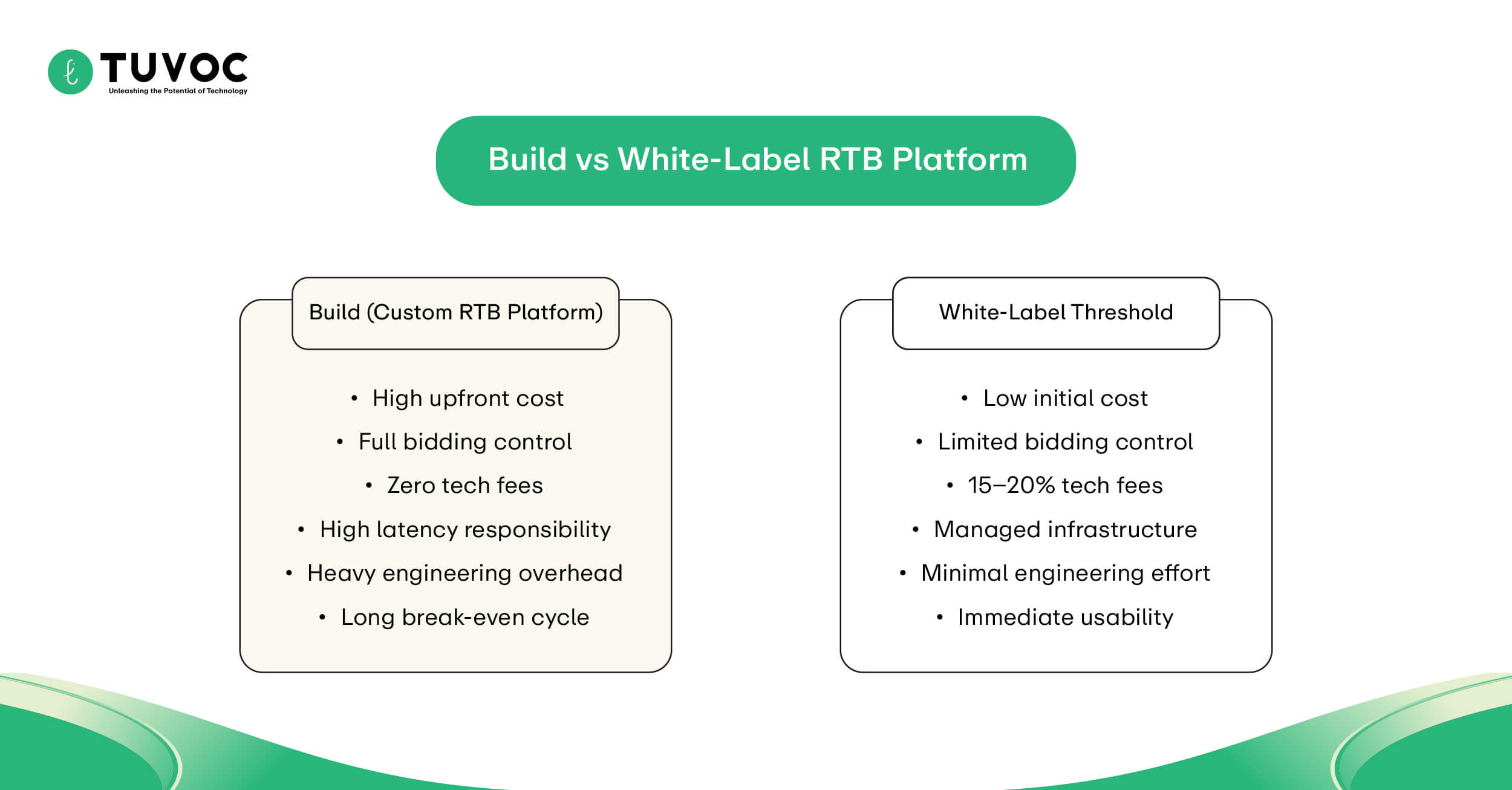
Build vs White-Label Threshold
| Metric | White-Label DSP | Custom RTB Build |
|---|---|---|
| Monthly Spend | <$100k | >$100k |
| Tech Fee | 15–20% | 0% |
| Dev Cost | None | $1M+/year |
| Control | Limited | Full |
| Break-Even | Immediate | 12–24 months |
Minimum Scale and Spend Thresholds
You need volume. If you aren’t spending $100k monthly, the math fails. The build vs. buy RTB platform decision is purely about amortization of the dev team costs.
You need enough impressions to spread that fixed cost thin. Small players get crushed by infrastructure overhead immediately. It is not scalable downwards.
- Monthly Spend: You need at least $100k in media spend to break even on dev costs.
- QPS Volume: Infrastructure costs only make sense if you are processing massive bid request volumes.
Control vs Dependency Trade-Off
DSPs hide the logic. You want to bid based on your proprietary data? They won’t let you inject that custom code easily.
RTB platforms that you own allow total transparency. You change the algorithm on Tuesday. You see the result on Tuesday. No ticket support needed.
- Black Box: Third-party DSPs obscure the bidding logic and prevent custom optimization tweaks.
- Custom Logic: Owning the stack lets you inject proprietary user data directly into the bid decision.
Control Comparison
| Factor | Third-Party DSP | Custom Platform |
|---|---|---|
| Bidding Logic Access | Restricted | Full |
| Data Injection | Limited | Direct |
| Algorithm Tweaks | Vendor Ticket | Immediate |
| Transparency | Black Box | Full Visibility |
Margin Recovery and Long-Term ROI
The middleman takes 15%. Then the data provider takes 10%. Programmatic advertising is full of taxes. If you build, you reclaim that 25% instantly.
The capital expenditure is high upfront. But the operating expense drops significantly over three years. It is a long game.
- Tech Tax: Eliminate the standard percentage fees charged by every middleman in the chain.
- CapEx vs OpEx: Trade high upfront development costs for lower long-term operational fees.
Core Components of an RTB System Architecture
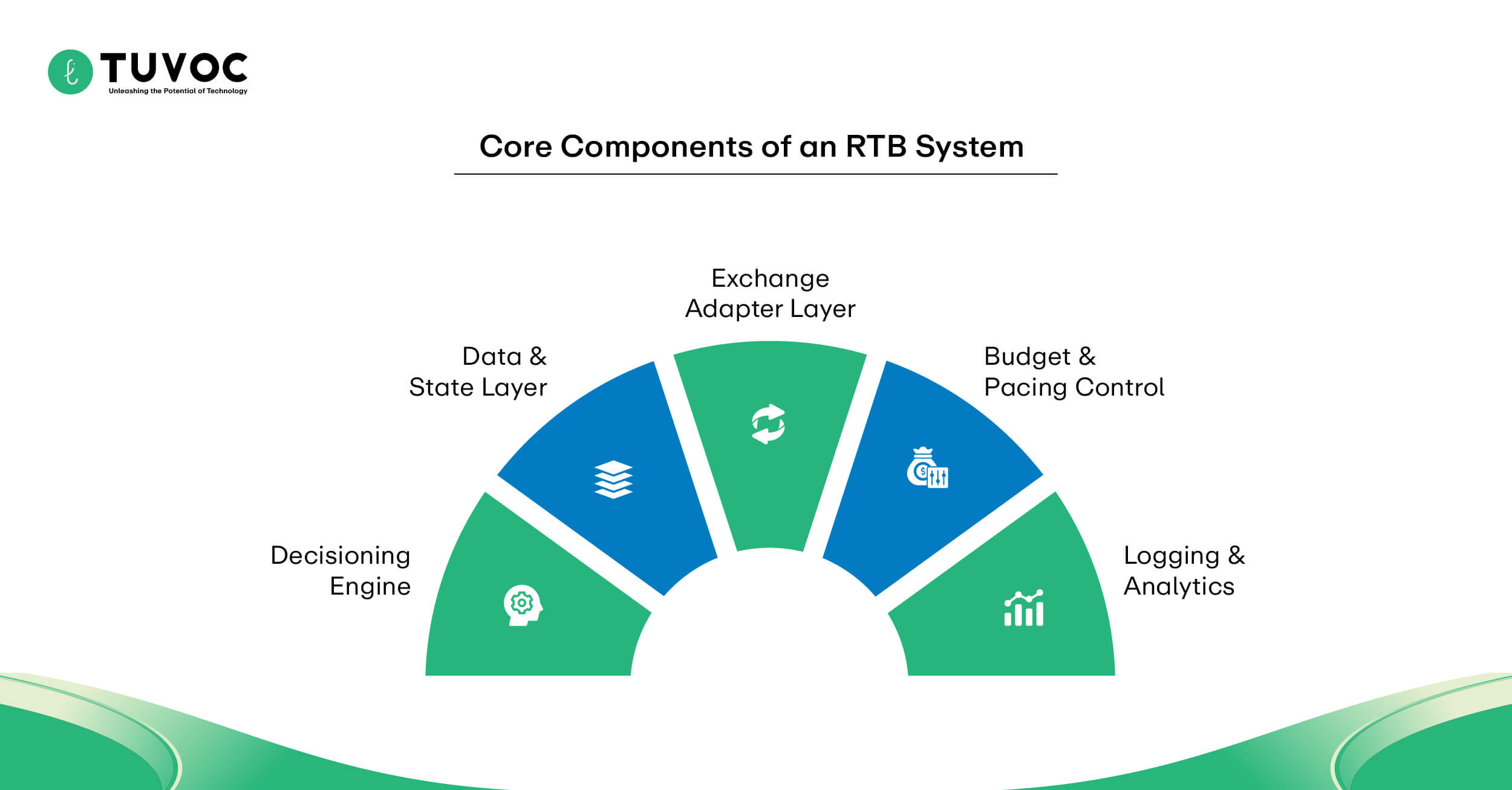
You think it is just a web server. It is a beast. RTB platform components must handle millions of requests per second without blinking. The architecture is not standard web app stuff. It is closer to high-frequency trading systems.
If you use a standard REST API pattern, you are dead on arrival. The programmatic supply chain punishes latency immediately. You need raw TCP sockets or gRPC. You strip everything down to the metal.
RTB Architecture Layers
| Layer | Purpose | Latency Budget |
|---|---|---|
| Ingress | Request intake | 5–10ms |
| Decision Engine | Bid logic | <10ms |
| Data Layer | User lookup | <1ms |
| Logging | Async write | Non-blocking |
| Exchange Adapter | Protocol normalization | 5ms |
Ingress Layer
The requests hit the load balancer first. It is a firehose. RTB streaming architecture cannot use standard Nginx configurations efficiently. You need a kernel. tuning to handle the open connections. You drop the slow connections immediately. It is brutal but necessary.
- Kernel Tuning: Optimize the network stack to handle massive concurrent connection volume.
- Load Balancing: Distribute incoming traffic evenly across the available bidder instances.
Decisioning Layer
This is the brain. It has 10 milliseconds to decide. RTB bidding engine design relies on in-memory computation entirely. No database calls allowed here.
If you query a disk, you time out. The logic must be instant.
- In-Memory Logic: All bidding decisions must happen in RAM to avoid latency.
- Timeout Enforcement: Hard limits on execution time prevent the entire system from lagging.
State and Data Layer
User data lives in Aerospike or Redis. It must be instant. AdTech reference architecture separates the cold storage from the hot path. You cannot wait for an SQL query to finish. The budget counters update in real-time. Consistency is hard here.
- Hot Storage: Use Redis or Aerospike for sub-millisecond data retrieval.
- Budget Counters: Atomic updates prevent overspending the advertiser’s daily budget cap.
Logging and Analytics Layer
Did you win the bid? Great. Now log it. Programmatic ad infrastructure generates terabytes of logs daily. You need Kafka to ingest the firehose before it crashes the disk.
The analytics run later. The write speed is the only priority.
- Kafka Ingestion: Buffers the massive stream of log data to prevent data loss.
- Async Writes: Logging must never block the main bidding thread execution.
Exchange Connectivity and Adapter Architecture
OpenRTB is a lie. It is not a standard; it is a loose suggestion. Every exchange implements it slightly differently, breaking your code constantly. When you build RTB platform connectors, you are writing custom translation layers, not simple plug-and-play drivers. The data fields move around without warning.
If you rely on contextual targeting, the category keys are different in every single request. Google sends them one way. Rubicon sends them another. You spend half your engineering time just normalizing the incoming chaos into something your engine can actually read.
OpenRTB Variations and Spec Deviations
The spec document says a field is “optional.” The exchange treats it as “mandatory.” OpenRTB implementation is a minefield of undocumented requirements and surprise changes. One partner sends the device ID as a string; the next sends it as an integer. It crashes the parser immediately.
You have to write exception handlers for every single partner connection. The documentation is usually outdated before you even read it.
- Field Mismatch: Data types often differ between exchanges despite the shared spec.
- Missing Signals: Critical targeting keys are frequently omitted by specific SSPs randomly.
Adapter and Gateway Normalization Layer
You cannot write logic for ten different formats. You need a gateway. It takes the mess from the DSP and SSP connection and cleans it instantly.
It converts everything into one internal canonical format that your bidder understands. If you skip this, your core code becomes a spaghetti mess of if-statements. The adapter pattern saves your sanity and keeps the core clean.
- Normalization: Convert diverse exchange payloads into a single internal data structure.
- Sanitization: Strip out malformed or dangerous data before it hits the core.
JSON vs. Protobuf Handling
JSON is human-readable. It is also heavy and slow. Protobuf is binary and fast. Your bid response needs to use Protobuf for the high-volume partners to save bandwidth.
The CPU cost of parsing JSON at scale is massive. You support both. You debug with JSON. You trade with Protobuf. It is the only way to scale without burning cash.
- Bandwidth Cost: Binary formats like Protobuf reduce network transfer fees significantly.
- Parsing Speed: CPUs decode binary data much faster than text-based JSON.
Serialization Comparison
| Format | Speed | Bandwidth | CPU Cost | Debuggability |
|---|---|---|---|---|
| JSON | Slow | Heavy | High | Easy |
| Protobuf | Fast | Light | Low | Harder |
Bid Request Handling and Real-Time Processing Layer
Handling 10,000 requests per second is a rounding error in this industry. Real scale starts much higher. RTB request processing systems must ingest 100,000 QPS without a single thread locking up. If the server blinks for a microsecond, you miss the auction entirely.
The ad request lifecycle is brutal and unforgiving. You have mere milliseconds to parse, decide, and respond before the timeout kills the connection. Any inefficiency in the code multiplies instantly across the cluster. You optimize for the worst-case scenario, or you crash immediately.
L4 vs L7 Load Balancing Strategies
L7 is smart but slow. It looks at the content. L4 is dumb and fast. It just moves packets. High QPS server architecture usually forces you to drop L7 logic at the edge entirely.
You cannot afford to parse HTTP headers when the firehose is fully on. The CPU cost of inspecting packets is too high. You route by IP and port only.
- Layer 4 Speed: Routes raw packets based on IP without inspecting data.
- Layer 7 Drag: inspecting content adds fatal latency under heavy load.
Connection Management and Keep-Alive Handling
Opening a TCP handshake takes time. You don’t have time. The RTB platform for high QPS traffic relies on persistent pipes. You keep the connection open.
You force the kernel to use the same socket for the next request immediately. If you close it, you pay the latency tax again. The overhead kills the throughput.
- Persistent Links: Never close the connection after a single bid request.
- Socket Cycling: Force the system to reuse the open port immediately.
Thundering Herd Mitigation
A million users arrive at once. The servers wake up and crash. High-throughput RTB systems need jitter. You cannot let every thread fight for the same resource simultaneously.
You have to stagger the wake-up calls, or the CPU locks up completely. The system freezes under its own weight.
- Random Jitter: Stagger thread wake-up times to stop resource contention.
- Load Shedding: Drop excess traffic instantly to save the core system.
Auction Engine Design and Decisioning Logic
The engine is the profit center. If your DSP bidding logic is weak, you buy trash. If it is too slow, you buy nothing. The decision system takes a chaotic request and turns it into a precise financial commitment in under 10 milliseconds. It is high-stakes gambling at light speed.
You cannot rely on static rules. Bidding algorithms must adapt to market pressure instantly. If the clearing price spikes, the engine must back off or double down based on the predicted user value. It is a constant war for margin.
Feature Extraction and Pre-Processing
The raw request is useless noise. You have to strip the user agent and IP into vectors instantly. Impression-level bidding relies on these clean signals to predict the click probability.
If you feed garbage into the model, you get garbage bids out. The transformation must happen in microseconds. You map the categorical text to integers before the model even sees it.
- Vectorization: Convert raw categorical data into numerical arrays for the model.
- One-Hot Encoding: Transform sparse features into readable signals for the algorithm.
Inference Latency Constraints
You have a 10 ms budget. That is it. If your model takes 12 ms, you time out. Real-time bidding logic forces you to use lighter models like logistic regression over deep neural networks. You trade accuracy for speed every time.
A perfect prediction that arrives late is worth zero dollars. You cut the layers down until it runs fast enough.
- Inference Trimming: Strip redundant model nodes to decrease the total calculation time.
- Precision Reduction: Convert model parameters to maximize processor throughput and efficiency.
No-Bid Filtering Layer
Why run the model if the user is from a blocked geo? Low-latency RTB system design puts a hard gate at the front. You drop 80% of requests before they touch the CPU.
It saves the expensive compute time for the bids that actually might win. You filter aggressively. If the user has no cookie, you drop them instantly.
- Geo Blocking: Drop requests from unsupported countries before processing starts.
- User Filtering: Ignore requests without a valid user ID or cookie.
Bid Price Computation Strategy
The model says the user is worth $5.00. You don’t bid $5.00. Bid shading algorithm design cuts that price down to $3.01 to beat the second-highest bidder. You optimize for the margin.
Floor price optimization data tells you the minimum you can get away with. You capture the spread between value and cost.
- Shading Logic: Lower the bid price to capture the surplus value.
- Pacing Control: Stop bidding if the daily budget is burning too fast.
Distributed Budget Management and Pacing Architecture
You have servers in Tokyo and servers in Virginia. They both spend the same advertiser’s budget at the exact same millisecond. If you build RTB platform logic without a synchronized controller, you overspend significantly in seconds. The latency between regions creates a massive risk.
Traffic shaping controls the spend rate effectively. You need a pacing layer that updates the balance across oceans. If the Tokyo server exhausts the daily cap, the Virginia node must stop bidding immediately to prevent financial loss. The synchronization is complex.
Strong Consistency vs Eventual Consistency
Perfection slows down the system. Real-time bidding cannot wait for a global database lock on every single request. You must accept slight data delays to keep the auction running. Eventual consistency allows the bidders to operate without blocking. You fix the balance later.
- Latency Delay: Waiting for global locks adds fatal milliseconds to the process.
- Soft Limits: Allow minor overspending to ensure the system remains responsive.
Consistency Trade-Off
| Model | Latency | Budget Accuracy | Use Case |
|---|---|---|---|
| Strong | High | Perfect | Finance |
| Eventual | Low | Minor Drift | RTB |
Distributed Counters and Atomic Updates
Reading and writing separately causes errors. Distributed budget pacing algorithm logic uses atomic counters in Redis to prevent this. The update happens in one single, locked step. Lua scripts enforce the rules directly on the cache.
- Atomic Write: Updates the budget counter in one step to prevent errors.
- Server Scripting: Runs the logic on the cache to avoid a network round-trip.
Regional Sharding and Global Spend Control
Tokyo gets $100. Virginia gets $100. They run alone. Scalable RTB architecture for AdTech uses pre-allocated slices to avoid constantly checking the central database.
When the local funds run out, they ask for more. This reduces the network load.
- Local Allocation: Assign specific budget chunks to regions to reduce synchronization.
- Background Refill: Request more funds asynchronously before the current slice empties.
Data Management and User Identity Layer
The user profile is the most critical asset in the system. You need to know who the user is before the auction timer runs out. User profile store architecture must handle millions of reads per second without failing. If the database is slow, the bidder times out, and the opportunity is lost forever.
Identity resolution is difficult because users switch devices constantly. You must link a mobile phone to a desktop browser in real time. The system needs a unified view of the user to bid accurately. This requires a complex data pipeline that merges different signals into one ID.
The Hot Store (Low-Latency KV Layer)
You cannot use a standard hard drive for this. Low-latency databases for RTB systems require everything to live in memory or on high-speed NVMe storage. The read operation must finish in less than one millisecond.
If the lookup takes longer, the bidding logic fails. You trade storage cost for raw speed. The data is ephemeral and fast.
- In-Memory Speed: Store active user profiles in RAM for instant access.
- Sub-Millisecond Read: Retrieve data faster than the auction timeout limit allows.
The Cold Store (Data Lake Architecture)
You move the old data out of memory. User profile store architecture splits the data into hot and cold tiers to save money. The cold store holds petabytes of historical logs on cheaper object storage.
This data is used for training machine learning models later. It does not need to be fast. It just needs to be scalable and cheap.
- Object Storage: Use cheap storage buckets for massive historical data retention.
- Model Training: Access this data offline to improve future bidding algorithms.
Feature Store Architecture
The model needs the same data during training and bidding. Post-cookie identity resolution in RTB relies on a feature store to keep these definitions consistent. If the training data differs from the live data, the predictions fail.
Audience segmentation logic calculates features once and serves them everywhere. It prevents logic drift between the data science team and the engineering team.
- Consistent Logic: Ensure training features match production features exactly.
- Reuse Features: Calculate a user segment once and leverage the same everywhere.
Infrastructure Requirements and Scalability Planning
You cannot put this on a standard web server. RTB platform scalability is a physics problem. You place the metal next to the exchange, or you die. If the data travels 50 milliseconds, the auction is already closed.
Cache-based bidding demands instances with massive memory and high network throughput. You need specialized hardware to handle the load. A poor architectural choice creates immediate latency and missed opportunities.
Geo-Routing and Colocation Strategy
If the exchange is in Virginia, your servers must be in Virginia. RTB platform architecture on AWS requires you to select the exact availability zone. You cannot route traffic across the country.
Network latency causes immediate failure in the auction. You must move the computing power to the data source.
- Zone Proximity: Place servers in the exact same region as the exchange.
- Distance Penalty: Every mile of fiber adds latency you cannot afford.
Auto-Scaling and Capacity Planning
The load curve is vertical. How to design a scalable RTB system involves using predictive auto-scaling rules. You cannot wait for the CPU usage to maximize. You must launch new instances before the load hits. Reactive scaling is often too slow.
- Predictive Scale: Boot up servers before the traffic surge actually begins.
- Warm Pools: Keep initialized instances ready to take traffic immediately.
Egress Cost Optimization
Cloud providers charge fees for every byte of data that leaves the network. Reducing cloud egress costs is critical for financial survival. You cannot send large, uncompressed JSON payloads.
You must compress the response data. Removing unnecessary fields saves significant money over millions of requests.
- Payload Trim: Cut optional fields to shrink the data transfer size.
- Compression: Compress the response of data to reduce monthly bandwidth cost.
Observability, Monitoring, and Distributed Tracing
You lose revenue if you cannot see the system internals. Distributed tracing for RTB is the only way to identify the exact source of a delay. You cannot search a text log that expands by gigabytes every minute. It is physically impossible to find the error manually.
The system moves too fast for human review. You need software that tracks the request path automatically with real-time analytics. If you rely on standard logging, you will never find the bottleneck.
Distributed Tracing Architecture
The request hits the gateway. You attach a unique ID immediately. Distributed tracing for RTB tools visualizes the time spent in each service. You see exactly which database call paused the execution. Without this link, the error logs are disconnected. You cannot see the cause and effect.
- Correlation ID: Assign a unique label to every request to track its journey.
- Service Graph: Visualizes the dependencies to locate the specific failing node.
Real-Time Metrics and Alerting
Averages are useless here. RTB latency optimization focuses on the 99th percentile. You must watch the slowest requests. These are the ones causing timeouts.
If the error rate jumps to 1%, the alert must fire. You cannot wait for a daily report.
- Tail Latency: Monitor the slowest 1% of traffic to catch timeout issues.
- Instant Paging: Trigger an alert immediately when the error threshold breaks.
Latency Budget Breakdown Analysis
You have a total budget of 100 ms. Low-latency bidding requires you to assign a strict limit to every function. The network gets 20 ms. The model gets 10 ms.
If a database query takes 15 ms, the bid fails. You have to audit the timing of every single step.
- Strict Caps: specific time limits for every internal operation.
- Path Audit: Review the execution speed of each function to remove waste.
Security, Compliance, and Fraud Controls
If you build RTB platform infrastructure, you paint a target on your back. Hackers flood the gateway with garbage to kill the latency. You have to scrub the pipe before it touches the wallet.
Cookie-less advertising strips away the easy verification data. You fly blind. Assume the traffic is hostile. You cannot view security as a feature. It is the only thing keeping the servers online. You filter the noise, or you crash.
Input Validation and Request Sanitization
Trust is zero in this environment. The request payload often hides malicious code or broken headers designed to crash the system. Ad fraud prevention modules must operate at the network edge to catch the poison before it enters.
You drop the bad payloads instantly. If you parse them, you waste expensive cycles on garbage.
- Strict Schema: Reject any request that fails the format check immediately.
- Code Scrub: Strip executable scripts from text fields to stop injection.
Privacy Signal Handling and Consent Enforcement
The legal risk is fatal here. If you ignore the consent string, the fines will destroy your margin. Real-time bidder architecture must decode the GDPR signal instantly and check the permission strictly.
If the user said no, you do not touch the data. You bid blind, or you pass.
- TCF Logic: Parse the consent string to verify what data you can use.
- Data Lock: Block access to user identifiers if the consent is missing.
Invalid Traffic Detection Integration
Bots burn your cash. They generate fake clicks to steal the budget. RTB platform components require a hard filter before the model even runs. You identify non-human IP addresses and block them.
You drop the connection immediately. You do not pay for fake views.
- IP Block: Filter known data center IP ranges out of the auction.
- Bot Filter: Drop requests that lack human interaction signals.
Development Phases and Engineering Milestones
You cannot build this in a sprint. The RTB platform development timeline is always double the estimate. You start with a prototype that barely functions. Then you spend six months fighting latency.
It is a slow crawl. You verify user targeting signals are reading correctly before you spend real money. If you rush, you burn the budget on bugs.
MVP Scope Definition
Strip it down. How to build a custom RTB platform begins with a static response. Forget machine learning. You just need to prove the pipes work. If the connection holds, you add brains later. A dumb bidder is enough to test.
- Static Bid: Send a fixed price to verify the network connection.
- Log Check: Ensure every request is recorded accurately to disk.
Internal Testing and Benchmarking
Simulate the crash. RTB request processing requires synthetic traffic that exceeds your peak. You hunt for the breaking point. The system will fail. You need to find the exact QPS at which the memory leaks.
- Load Gen: Blast the servers with fake requests to find limits.
- Leak Check: Watch RAM usage during high-pressure stress tests.
Incremental Feature Expansion
Now you add intelligence. You slowly introduce DSP bidding logic to predict value. You deploy a simple regression model first. Do not use neural nets yet. You test one feature to isolate the specific gain.
- Basic Model: Deploy a simple algorithm to fix the win rate.
- Split Test: Compare the new logic against the random baseline.
Shadow Mode, Traffic Replay, and Pre-Production Validation
Deploying straight to production is professional suicide. Shadow bidding implementation provides the only safety net that functions in this high-frequency environment. You see the decisions happen in real-time without spending a cent of the budget.
The simulation must run in parallel. You check if your bid shading logic is actually saving margin or just losing auctions. The test environment must mirror reality perfectly, or the data becomes a dangerous lie.
Validation Framework
| Mode | Live Spend | Risk | Purpose |
|---|---|---|---|
| Traffic Replay | No | Low | Parser validation |
| Shadow Mode | No | Low | Logic testing |
| Production | Yes | High | Revenue generation |
Traffic Replay Systems
You take yesterday’s firehose and point it at today’s code. Traffic replay system design lets you crash the server safely in a sandbox environment before the client knows.
You need to see if the new parser handles the weird edge cases from the wild. It catches the regressions instantly. You verify the fix works without risking a single dollar of the active media budget.
- Log Injection: Re-feed historical bid requests into the new system version.
- Regression Check: Compare the new output against the old production logs.
Shadow Bidding Mode
The system receives real traffic and makes real decisions. It just doesn’t send the final network packet out. Shadow bidding implementation runs purely in the logs to verify the logic against live market conditions.
You compare the shadow wins against the live wins. If the shadow bidder outperforms the legacy system, you swap them. It is a risk-free trial that proves the math works.
- Silent Mode: Process live requests fully but suppress the final outbound packet.
- Logic Verify: Confirm the bidding algorithm behaves correctly on real-world data.
Stability and Win-Rate Verification
You have to prove the win rate holds up under fire. RTB platform scalability isn’t just about raw speed; it is about absolute consistency when the load triples. You watch the shadow metrics like a hawk for a full week.
If the error rate flickers even once, you abort the launch immediately. You cannot fix a live bidder while it bleeds the client’s cash.
- Stress Test: Hammer the servers for a week to expose memory issues.
- Rate Match: Ensure the shadow win rate matches the expected baseline.
Estimated Cost Breakdown by Component
You want to know how much does it cost to build a DSP? Stop dreaming about a cheap MVP right now. The entry ticket is millions, not thousands. The AdTech ecosystem taxes you efficiently at every single layer of the stack. You have the initial build cost, which burns cash for a year.
Then you have the operational burn, which never ends. You are paying for top-tier engineers and premium bandwidth simultaneously. It is a financial furnace. If you don’t have $2M liquid, don’t even start the architecture diagram.
Annual Cost Estimate
| Component | Estimated Cost |
|---|---|
| Engineering Payroll | $1M+ |
| Cloud Infra | $600k |
| Egress Fees | $300k |
| Fraud / Data Feeds | $200k |
| Certification | $50k |
| Total | $2M+ |
Engineering Team Costs
You cannot hire average web developers here. The cost to build an RTB platform is driven primarily by high-performance systems engineers who know Rust or Go.
You need a data scientist, a backend lead, and a DevOps maniac immediately.
They cost $200k each minimum. You burn $1M a year on payroll before you even buy a server.
- Specialist Salary: High-frequency trading engineers command massive premiums over standard full-stack developers.
- Burn Rate: The monthly payroll expense is your highest fixed cost during development.
Infrastructure and Cloud Costs
The cloud bill is the silent killer. Ad tech infrastructure costs scale linearly with traffic, not with your revenue. You pay for the ingress and egress of terabytes of data daily.
Spot instances help, but the bandwidth fees are non-negotiable. You will spend $50k monthly on AWS just to keep the lights on.
- Egress Fees: Data transfer costs accumulate rapidly when serving billions of bid responses.
- Compute Scale: High-memory instances for caching drive up the hourly compute rate.
Third-Party Services and Compliance Costs
You need external data to bid intelligently. The ad exchange requires you to certify your bidder, which costs money and engineering time. Then you pay for fraud protection fees every month.
These are recurring subscriptions that eat your gross margin. You pay them whether you win the auction or lose it.
- Data Feeds: Third-party audience segments and fraud lists charge monthly licensing fees.
- Certification: Exchanges charge fees to test and certify your bidder connection.
Typical Development Timeline from MVP to Production
Building this takes massive effort. If you plan to build RTB platform technology from scratch, expect a nine-month timeline. You spend the first quarter just stabilizing the network layer.
Custom RTB platforms frequently miss launch dates due to hidden complexity. You might plan for a Q1 launch, but you will not trade significant volume until Q3. The technical hurdles always cause unforeseen delays.
Certification Phase with Exchanges
You do not just connect and bid. The DSP certification process involves a strict audit by the exchange to ensure your system is stable. They test your timeout rates and error handling for weeks. If you fail the compliance check, they block your access. You fix the bug and wait again.
- Audit Queue: Exchange certification testing often takes several weeks to complete.
- Error Check: You must pass strict validation of your response formats.
Warm-Up and Gradual QPS Ramp
You cannot accept full traffic immediately. Auction mechanics require warm caches to operate at low latency. If you send 50,000 requests to a cold system, the response time spikes and the bids fail.
You must increase the load slowly over several days. The database needs time to load user profiles into memory.
- Cache Warming: Gradually fill memory with active user data to avoid lookups.
- Step Ramp: Increase traffic volume in small increments to monitor stability.
Full Production Rollout
You remove the manual safeguards now. AdTech microservices architecture must handle peak loads automatically. You stop watching the logs manually and trust the automated alerts to catch issues.
The system operates independently and spends the budget in real time. You must optimize performance constantly to maintain the margin.
- Auto-Scale: Enable dynamic server allocation to handle sudden traffic surges.
- Live Monitor: Switch to automated alerts for any latency violations.
FAQs
In-house systems are essential when your specific dataset or niche business strategy requires custom bidding math that generic, one-size-fits-all algorithms are unable to execute.
Renting a platform accelerates your launch, yet it denies you the ability to rewrite core code or optimize the underlying infrastructure for specific performance gains.
You need a high-speed request handler, a core logic unit for pricing, and a synchronized pacing service to prevent budget overruns across distributed regions.
Pair high-performance compiled languages for the bidder logic with ultra-low-latency NoSQL databases for user profiles and distributed memory caches for real-time budget tracking.
These environments provide the granular memory management and raw execution velocity required to process massive concurrent loads while keeping internal logic under a 10 ms ceiling.
Manoj Donga
Manoj Donga is the MD at Tuvoc Technologies, with 17+ years of experience in the industry. He has strong expertise in the AdTech industry, handling complex client requirements and delivering successful projects across diverse sectors. Manoj specializes in PHP, React, and HTML development, and supports businesses in developing smart digital solutions that scale as business grows.

Have an Idea? Let’s Shape It!
Kickstart your tech journey with a personalized development guide tailored to your goals.
Discover Your Tech Path →Share with your community!
Latest Articles

Staff Augmentation Is Broken for AI: What Actually Works in 2026
Why Traditional Staff Augmentation Fails in AI Projects Most teams don’t set out with a flawed approach. In fact, the…

Ad Fraud Prevention Strategy 2026 | Detection, Compliance & Revenue Protection
Why Ad Fraud Prevention Requires a Strategic Shift in 2026 Ad fraud prevention strategy in 2026 isn't a detection problem…

AI-Driven Ad Fraud Detection | From Bot Identification to Real-Time Protection
The Evolution from Rule-Based Detection to AI Systems AI ad fraud detection failed first with rules. Write a filter for…
