
How to Build a Custom DSP Platform | Features, Cost & Architecture

Manoj Donga
AdTech
Published : Feb 9, 2026

Key Takeaways
- Hardware Bottlenecks: Realizing exactly when a standard commercial seat starts to throttle your incoming data and kill your performance.
- Volume Handling: The literal server and software requirements for managing huge bid streams without losing auction speed.
- Build vs. License: Knowing which parts of the stack are worth your engineering hours and which parts are just generic commodity code.
- Cost Recovery: Removing the hidden fees and vendor-side data filters that usually eat up your media margins.
When Building a Custom DSP Becomes Necessary
Deciding how to build a DSP is usually a move born out of frustration with the limitations of existing demand side platform companies. You hit a technical ceiling when your proprietary bidding logic requires data signals that the commercial user interface simply doesn’t surface or support. At this point, you aren’t just looking for a new vendor; you are looking for a way to own the underlying decision-making engine and the server-side infrastructure.
When your media spend reaches a certain volume, the percentage-based fees paid to a provider often outweigh the engineering costs of maintaining your own private stack. Transparency becomes a financial imperative rather than a luxury.
Ownership allows you to strip away the unnecessary features and focus entirely on the specialized bidding paths that drive your specific business outcomes. This shift happens when the platform begins to limit your growth rather than enabling it.
Platform Constraints That Signal the Need for Customization
Standard platforms often engage in aggressive bid request processing filters to keep their own server costs down. This means they might drop incoming opportunities from niche publishers before your account ever sees them. If your strategy relies on very specific, low-volume inventory, you might find that a commercial seat is essentially hiding the traffic you want to buy most.
When you cannot access the raw, unfiltered bid stream, your algorithms are working with a partial data set. You are essentially paying for a curated view of the market rather than the market itself.
- QPS Limits: Your vendor might cap how many auctions you can see per second to save their own hardware costs.
- Data Stripping: The platform often removes the very metadata your custom model needs to calculate a precise bid value.
Scale, Control, and Transparency as Build Triggers
Successfully scaling a DSP beyond initial RTB throughput requires an infrastructure capable of handling millions of events per second without crashing. Most businesses reach this trigger when they realize their current provider is taking a significant margin on every impression while providing zero visibility into the actual clearing prices.
You need a system that gives you the keys to the log-level data without charging an extra “transparency fee.” Control over the bid logic is the difference between following a vendor’s “auto-optimization” and executing your own mathematical edge.
- Server Debt: Moving out of shared cloud spaces into your own dedicated clusters so you can keep response times under the 100ms limit.
- Fee Extraction: Deleting that 15% platform take-rate so you can put that money straight back into more ad impressions.
Deciding What to Build vs What to Integrate
The choice between white-label vs. custom DSP development for agencies often comes down to where you want your intellectual property to live. You don’t necessarily need to build the user interface or the reporting dashboard from scratch if your value is in the bidding algorithm itself.
Many firms decide to code the “brain” of the bidder while plugging into third-party APIs for the generic stuff. Using a white-label foundation can save years of dev time if the platform lets you inject your own code into the bidding layer.
- Hybrid Stack: You code the decision-making engine but use existing vendors for the data hosting and the creative pixels.
- Bidding Frameworks: Leveraging a pre-built RTB framework to handle the complex handshakes while you focus on the custom math.
Core Components of a Custom DSP Platform
Knowinghow to build a DSP requires moving beyond the buyer’s interface to understand the literal machinery that makes a bid decision in under 100 milliseconds. You are essentially building a high-frequency trading system that must ingest, filter, and respond to millions of bid requests per second across a globally distributed infrastructure.
If the bidder cannot reconcile your data segments with an incoming auction signal in real-time, the entire stack fails. The architecture is a balance between massive data storage and ultra-low-latency processing. You need a setup where the bidder is decoupled from the reporting database so that a heavy analytics query doesn’t slow down your active auctions.
Bidder, Data Layer, and Control Interfaces
The bidder is the front-line engine of your demand side platform architecture, handling the raw OpenRTB handshakes with exchanges. It sits on top of a data layer, usually a high-speed cache like Aerospike, that stores user segments for instant lookup during the auction.
If the connection between the bidder and this profile store lags by even 10ms, you’ll miss the bid window and the impression is lost. You also need a separate control API so your traders can update budgets without hitting the bidder’s core processing threads.
- Bid Decisioning Logic: The actual code that parses the JSON payload from the exchange and checks it against your targeting rules.
- Low-Latency Profile Store: A dedicated database meant for sub-millisecond lookups of your first-party audience IDs.
Supporting Services for Optimization, Reporting, and Governance
Reliable DSP analytics and reporting shouldn’t just be a static dashboard; it has to be a live feedback loop for your bidding models. You need a “listener” service that grabs win notices and conversion pixels to tell the bidder which inventory is actually working.
If this data pipeline is slow, your bidder keeps spending money on “junk” traffic because it hasn’t received the signal to pivot yet. Governance layers sit in the middle to make sure you aren’t bidding on blocked domains or violating privacy rules.
- Win-Loss Signal Pipeline: The service that catches real-time pings from the exchange to track your actual spend and win rates.
- Cold Storage Warehouse: A separate database for long-term logs so your analytics team can run heavy SQL queries without breaking the live bidder.
External API Layers for Campaign Control and Reporting
A functional AdTech DSP solution has to be “headless” to be truly scalable. You need an API layer that lets external scripts or internal tools push new creative assets and pull performance stats without anyone logging into a UI.
This is how you automate bid adjustments based on real-world triggers like stock prices or inventory levels in a warehouse. Keep your API documentation simple and updated or your dev team will get stuck manually fixing integration bugs every week.
- Campaign Management Endpoints: The specific API calls used to create or pause line items programmatically.
- Log Export Workers: Background processes that move raw auction data into your own S3 buckets for offline modeling and audit.
SSP and Exchange Integration Architecture
Securing supply-side platform (SSP) connectivity is not a simple “plug and play” task. It requires a heavy engineering focus on how you parse incoming bid requests at massive scale. If your bidder relies on standard JSON for every handshake, the sheer size of the data will eventually cause your network costs to spike and your latency to creep over the 100ms limit.
Moving to protocol buffers (Protobuf) is the only way to keep the payloads compact enough for high-frequency trading. Binary serialization is a requirement, not a suggestion, for anyone building for global scale. You are essentially trading human-readability for the raw speed needed to keep your bid-win ratios healthy across competitive exchanges.
Deciding What to Build vs What to Integrate
| Component | Build (Custom) | Integrate (White-Label/API) |
|---|---|---|
| Bidding Logic | Proprietary math & bid shading | Standard weighted averages |
| User Interface | Specialized trader dashboards | Generic campaign management UI |
| Reporting Engine | Log-level data ownership | Aggregated dashboard views |
| Data Sync | Deep CRM/CDP integration | Standard pixel-based syncing |
OpenRTB and Media Protocol Implementation Considerations
A functional Real-time Bidding integration lives or dies by its strict adherence to the OpenRTB spec. You’ll find that while the industry claims to be on version 2.6, different exchanges have their own “flavors” of the protocol that can break a generic bidder.
If your parser fails to recognize a required field or a new object, the SSP will simply drop your bid without telling you why. The bidder must be able to handle version mismatches without crashing the entire processing thread.
- Spec Validation: Writing strict code that checks every incoming JSON or Protobuf object for compliance before it hits the bidding logic.
- Latency Budgets: Monitoring the exact time it takes to deserialize a request; anything over 5ms is a failure in a high-speed environment.
Exchange-Specific Extensions and Adapter Maintenance
Most ad exchange integrations aren’t actually standard; they are a collection of custom extensions buried in the ext object of the bid request. These hidden signals often contain the data you need for things like video pod positions or proprietary brand safety scores.
You have to build and maintain separate adapters for every major partner or you’ll miss out on the very signals that make an impression valuable. Maintenance is a constant cycle because exchanges push updates to these custom objects whenever they launch new features.
- Custom Schema Mapping: You have to manually map the unique fields from SSPs like Magnite or Google to your internal data model.
- Adapter Isolation: Keeping each exchange connection in its own container or service so a bug in one doesn’t kill your entire bid stream.
Certification Cycles, Test Environments, and Ongoing Compliance
If you want to know how to certify a custom DSP with SSPs, prepare for weeks of sandbox testing. You have to prove that your bidder can handle a massive QPS (Queries Per Second) load without timing out or sending “garbage” responses.
Most SSPs will run you through a “penny-bidding” phase where they check your response speed and creative pixel reliability before they let you buy real traffic. If your error rates spike post-launch, you’ll be kicked back into a test environment and your traffic will be cut off until you fix the leak.
- QPS Stress Testing: Simulating a million requests per second in a staging environment to find out where your bidder’s memory leaks are.
- Creative Auditing: Every SSP has different rules for SSL pixels and VAST tags; you have to pass their automated scanners before your ads can go live.
Architecture Design Principles for Custom DSPs
At the engineering level, non-blocking I/O is a hard requirement to keep a slow database lookup from killing your entire bidding thread. When you are processing hundreds of thousands of requests per second, the bidder must initiate an external call and move straight to the next auction without waiting for a packet return.
If your logic waits for every sync, the resulting latency will force the exchange to drop your connection for being unresponsive. A decoupled approach lets you scale specific nodes based on traffic spikes. This prevents your infrastructure costs from spiraling as your QPS grows because you aren’t over-provisioning the whole stack just to handle one bottleneck.
Decoupling Bidding Logic from Data Persistence
A functional programmatic advertising architecture treats the bidder as a pure execution engine that never gets bogged down by write operations. You have to isolate the real-time bid decisioning from the database where you store long-term logs.
If the bidder tries to write to a slow disk during a win notice, the internal queue will back up and the system will time out. The goal is to keep the auction “hot path” entirely in memory while pushing logs to an asynchronous pipeline.
- RAM-Based Targeting: Stashing active campaign rules in Redis so the bidder doesn’t wait on a main disk response.
- Kafka Event Streams: Pushing raw auction signals to a background pipe so the main thread never stops to wait for a database write.
Designing Stateless and Fault-Tolerant Bidder Services
A stateless bidder design means any server in your cluster can handle any incoming request without needing a “history” of the previous auction. This lets you kill or reboot nodes in real-time without losing track of campaign pacing or accidentally overspending.
If the state of a campaign lives only on one machine, a simple hardware failure will break your entire pacing logic. Statelessness is the baseline for horizontal scaling, allowing you to spin up new instances in different regions as global traffic shifts.
- Shared Memory Store: Keeping global budget and frequency data in a centralized, ultra-fast store rather than on the local node.
- Rapid Boot Cycles: Ensuring the bidder can start up and fetch its config in seconds to handle sudden exchange traffic bursts.
Non-Blocking I/O for High-Concurrency Request Handling
In low-latency engineering, every microsecond spent waiting for a network socket is a microsecond you aren’t bidding. Non-blocking models allow your bidder to handle thousands of concurrent TCP connections on a single thread.
This efficiency is amplified by optimized payload serialization, which ensures the CPU spends as little time as possible turning JSON into internal objects. If your I/O blocks during a traffic surge, your win rates will crater as the exchange marks your seat as timed out.
- Concurrency Primitives: Using Golang’s channels or Netty’s event loops to manage thousands of simultaneous auction handshakes.
- Binary Formats: Swapping slow text-based JSON for Protobuf or FlatBuffers to minimize the CPU cost of request parsing.
Real-Time Constraints and Infrastructure Planning
When you commit to how to build a DSP, you are essentially signing up to manage a global infrastructure that never sleeps. The primary challenge isn’t just writing the code; it’s ensuring that your servers can ingest millions of requests per second without the network overhead eating your margins.
You have to account for the physical distance between your bidding clusters and the exchange’s data centers. If the round-trip time for a packet exceeds the 100ms threshold, your bidder is effectively invisible to the market. You are optimizing for throughput and stability across multiple continents simultaneously.
Solving for P99 Latency in Global Auction Environments
Developing a low-latency ad bidder requires a relentless focus on P99 response times rather than just the average. If 1% of your bids take 200ms because of a slow garbage collection cycle in your code, those auctions are guaranteed losses.
You need a runtime environment that prioritizes deterministic execution to ensure that every handshake completes before the exchange closes the door. Even a slight jitter in your network stack can cause a massive drop in win rates during peak traffic hours.
- Zero-Copy Parsers: Using data structures that allow the bidder to read incoming bid requests without moving data around in memory.
- GC Tuning: Stripping away heavy background processes to prevent the “stop-the-world” pauses that kill real-time performance.
Regional Cluster Deployment and Exchange Proximity
A distributed bidding cluster must be physically located in the same regions as the major supply-side platforms to minimize speed-of-light delays. If your bidder lives in Virginia but you are trying to buy inventory in Tokyo, the 200ms trans-Pacific lag makes the auction impossible to win.
You have to deploy localized “pods” that handle the heavy lifting of the auction while syncing only the essential budget data back to your central hub. Proximity is the only way to ensure your network latency stays under the 10-20 ms range required for a competitive edge.
- Geo-Sharding: Routing incoming traffic to the nearest regional data center based on the exchange’s endpoint location.
- State Syncing: Using a fast global backbone to update campaign caps across regions without blocking the local bidder’s threads.
Using Spot Instances Without Compromising Bid Stability
Building a cloud-based DSP architecture often involves a trade-off between server costs and auction reliability. Using spot instances can cut your compute bill by 70%, but you risk losing a massive chunk of your bidding power if the cloud provider suddenly reclaims that hardware.
You need a failover logic that can migrate traffic to on-demand instances or other regions the second a spot termination notice is received. A sudden loss of capacity shouldn’t result in a total blackout for your active campaigns.
- Graceful Draining: Implementing a system that stops accepting new bids on a node as soon as it receives a shutdown signal from the cloud provider.
- Hybrid Scaling: Mixing reliable on-demand servers for your “base” load with spot instances to handle the high-volume traffic spikes.
Security Architecture and Threat Mitigation
Hardening your security protocols for real-time ad bidding means moving beyond simple firewall rules to protect the integrity of your bid logic and data stores. Because your bidder is exposed to millions of external pings from various exchanges, every open port is a potential entry point for malicious actors.
You have to assume that any incoming payload could be a vector for an injection attack or a resource exhaustion attempt aimed at taking down your bidding cluster. Security must be baked into the networking layer to ensure that only verified exchange IPs can communicate with your bidder. This prevents unauthorized traffic from eating up your CPU cycles or probing your internal API endpoints for vulnerabilities.
Authentication, Authorization, and Access Control Surfaces
A privacy-first AdTech stack relies on physically isolating the bidder from the internal management dashboards. You shouldn’t have a single set of credentials that opens both the bidding engine and the financial databases.
Use short-lived tokens and service-to-service auth so that a breach in one regional cluster doesn’t compromise the whole global setup. Unshielded internal APIs are a massive risk. An attacker could potentially change bid prices or empty out campaign budgets if they find an entry point.
- Account Scoping: Hard-coding service permissions so they only fetch targeting configs or push logs and nothing else.
- Network Moats: Putting the bidder in a segmented zone away from the databases holding sensitive audience identifiers.
DDoS Mitigation and Traffic Filtering at Auction Scale
In high-concurrency bidding, a standard DDoS attack can be difficult to distinguish from a legitimate traffic spike from a major SSP. You need automated filtering that can identify and drop “junk” requests at the edge before they hit your core bidding logic and consume expensive memory.
If your system spends too much time trying to parse malformed or malicious packets, your legitimate win rates will drop as the bidder’s response time increases.
Rate limiting must be applied at the exchange level to prevent a single misconfigured pipe from overwhelming your entire regional cluster.
- Edge Scrubbing: Utilizing global load balancers that can drop non-OpenRTB compliant traffic before it reaches your application servers.
- Heuristic Filtering: Building logic that detects “impossible” bid request patterns, such as multiple requests for the same user ID from different geographic regions simultaneously.
Encryption and Data Protection Across Real-Time Pipelines
Protecting the data moving through your programmatic AdTech stack requires end-to-end encryption that doesn’t add significant latency to the auction. While HTTPS is the standard for the handshake, you also need to worry about how data is encrypted while “at rest” in your profile stores.
If an intruder gains access to your Redis or Aerospike clusters, unencrypted audience segments could lead to a massive regulatory nightmare under GDPR. The challenge is encrypting and decrypting data in micro-bursts without exceeding your sub-10ms processing budget for each request.
- TLS Edge Termination: Pushing the decryption load to the load balancer level so the bidder CPU stays focused on auction math.
- Partial Payload Encryption: Scrambling only specific user IDs instead of the whole packet to keep the processing overhead low.
Data Pipelines, Storage, and Signal Processing Layers
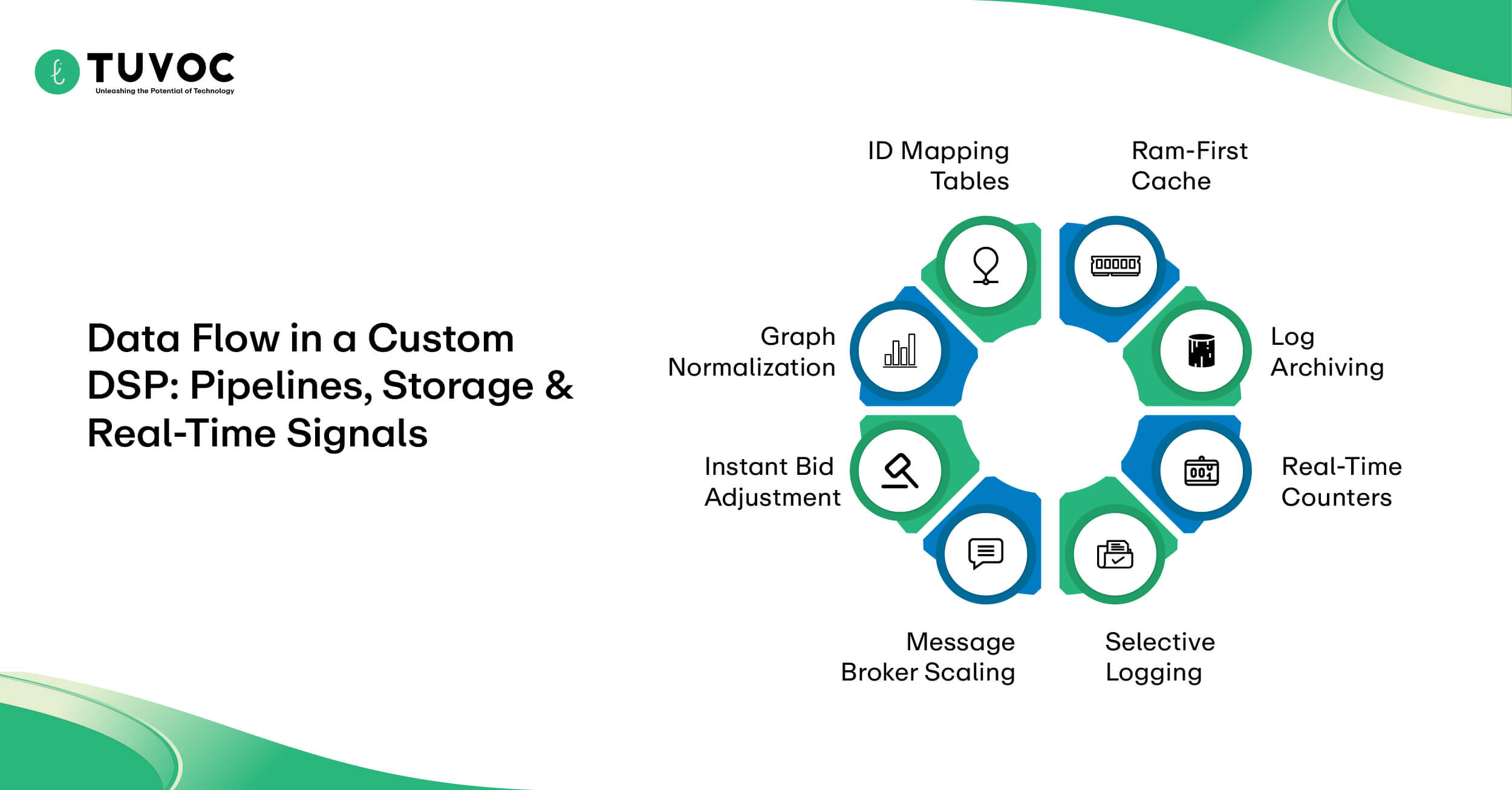
Custom engineering requires a hard split in your data management strategy. You have to implement hot path data storage for real-time auction validation while keeping a separate, massive architecture for long-term logic. Your bidder needs to pull user profiles and budget caps from a high-speed cache that supports millions of simultaneous lookups.
Relying on a traditional disk here is not an option because of the latency it introduces. Moving data between these systems is a major engineering hurdle. You are looking at a continuous data flow where every single auction result has to update the global bidder state across your entire regional network almost instantly.
Hot Path vs Cold Storage (Data Tiering)
| Tier | Storage Type | Purpose | Latency Target |
|---|---|---|---|
| Hot Path | In-Memory (Redis/Aerospike) | Real-time bid evaluation | < 1ms |
| UsWarm Path | SSD / Distributed SQL | Pacing & frequency counters | 10ms – 50ms |
| Cold Storage | S3 / Data Lake | Log-level auditing & ML training | Seconds/Minutes |
Hot Path vs Cold Storage in DSP Data Architectures
A functioning bidder relies on in-memory data stores like Aerospike or Redis to serve audience segments during the auction window. If the bidder has to wait on a standard database query to find out if a user is in a “retargeting” bucket, the 100ms timeout will expire before the bid is even formed.
You only keep the most critical, frequently accessed signals in the hot path to save on expensive RAM costs. Less urgent data, like historical campaign performance from last month, stays in cold storage until it’s needed for offline model training.
- RAM-First Cache: Storing only the active segment IDs and current line item balances for sub-millisecond retrieval.
- Log Archiving: Moving raw, multi-terabyte files to S3 or a data lake so the bidder memory stays lean and fast.
Stream Processing for Real-Time Pacing and Frequency Controls
Solid stream processing is the only way to handle global pacing and frequency capping and bid shading without losing control of the budget. You need a system that catches win notices immediately and updates every bidding node in your cluster.
If this feedback loop isn’t near-instant, separate servers might bid on the same ID at once and break your frequency caps. A laggy data stream means your bidder is essentially working with old info. This leads to overspending because the bidder hasn’t received the signal to pause or slow down yet.
- Real-Time Counters: Using a distributed engine to track how often an ID sees an ad in a one-hour window.
- Instant Bid Adjustment: Routing win prices back to the engine so the bid shading logic can pivot for the very next auction request.
Designing a Cost-Effective Log-Level Data Pipeline
A standard reference architecture for demand-side platform using kafka involves piping every auction event through a series of brokers for processing. The challenge is the sheer volume of data; logging every single bid request you don’t win will quickly bankrupt you in cloud egress fees.
You have to be selective about what data you keep, focusing on win notices, clicks, and conversion signals rather than the raw bid stream. Filtering and compressing these logs at the edge before they hit the central pipeline is the only way to keep the storage bill manageable.
- Message Broker Scaling: Clustering Kafka nodes across regions to handle the massive write-throughput of a global bidding operation.
- Selective Logging: Dropping redundant bid request metadata at the ingestion point to prioritize high-value performance signals.
Identity Resolution and User Graph Considerations
Managing first-party data onboarding means your system must be able to link various identifiers like hashed emails or device IDs back to a single user profile. This identity resolution happens outside the auction “hot path” because of the computational weight involved in traversing a complex user graph.
The result of this processing is then pushed to the bidder’s cache as a simple key-value pair for instant lookup. As third-party cookies disappear, your ability to reconcile these disparate signals becomes the core competitive advantage of your custom stack.
- Graph Normalization: Consolidating multiple device signals into a single “master ID” that the bidder can recognize in an OpenRTB payload.
- ID Mapping Tables: Maintaining a high-speed translation layer that converts SSP-specific IDs into your internal audience segments.
Privacy Compliance Architecture in Custom DSPs
Enforcing data sovereignty at the infrastructure level requires more than just regional hosting; it requires a bidding logic that respects the geographic origin of every request. You have to build the stack so that user identifiers never leave their legally defined boundaries during the auction process. If a bid request originates in the EU, your system must ensure that the processing and storage happen on local nodes that comply with regional mandates without leaking data to global clusters.
Managing these boundaries is a core technical requirement for high-volume traders. You are essentially coding a map of global privacy laws directly into your packet-routing logic to avoid accidental cross-border data transfers.
Processing Privacy Signals in Real-Time Bid Flows
A modern real-time bidding engine must parse and act on complex privacy strings, such as TCF v2.2 or GPP, in every single handshake. If the incoming payload lacks the necessary consent flags, your bidder has to automatically drop the request or strip out all personal identifiers before processing.
This logic has to happen at the very start of the auction pipeline to ensure you aren’t accidentally profiling users who have opted out. Failure to validate these signals instantly can lead to your bidder being blacklisted by major supply partners.
- String Parsing: Extracting consent bits from the OpenRTB regs and user objects to determine if a bid is legally allowed.
- Negative Targeting: Automatically excluding any request that carries a “Do Not Sell” signal before the bidder even looks at the audience segments.
Consent Enforcement Across Data and Decision Layers
Consent isn’t just a flag in the auction; it has to be synchronized across your entire database sharding strategy. You need a way to propagate a “right to opt-out” signal from your edge listeners back to the core profile stores where user data lives.
If a shard in your North American cluster still holds a profile that was deleted in the European shard, you risk a compliance breach during the next global campaign sync. Ensuring this consistency across a distributed system is one of the most difficult engineering tasks in the build.
- Shard-Level Purging: Implementing automated scripts that hunt down and delete user records across specific regional shards when a revocation signal is received.
- Consent-Aware Routing: Tagging every record in your high-speed cache with its original consent status so the bidder can check it in the hot path.
Data Deletion, Retention, and User Rights Fulfillment
Core demand-side platform features must include an automated pipeline for handling Subject Access Requests (SARs) and “Right to be Forgotten” pings. You cannot rely on manual SQL queries to find and delete user data across terabytes of log files and active bidder caches.
You need a centralized “deletion bus” that can broadcast a user ID to every component in your stack—from the cold storage logs to the real-time profile store. Automating this fulfillment is the only way to stay compliant without hiring a massive team of data engineers just to manage deletions.
- Automated Retention Hooks: Coding expiration dates into every user record so that data is purged the moment it reaches its legal age limit.
- Deletion Broadcasts: Using a message queue to ensure that once a user asks to be deleted, the signal reaches every regional bidding pod within minutes
Development Phases and Team Composition
Executing the plan for how to build a DSP requires a strict timeline that prioritizes the bidding core before the user-facing features. You cannot rush the initial architecture phase because any flaw in how your bidder handles the OpenRTB handshake will become an expensive technical debt once you scale to millions of requests.
The early months are dedicated entirely to throughput testing and ensuring your regional clusters can communicate without significant data lag. The project moves from a “sandbox” environment where you simulate exchange traffic to a “penny-buying” phase on live pipes. This transition is where most teams discover their first major bottlenecks in the data pipeline.
Phased Development from MVP to Production Scale
A functional roadmap for custom DSP development MVP centers on a “barebones” bidder that simply hits the 100ms response window. Forget the UI or the AI for now. The goal is strictly technical: prove your cluster doesn’t collapse under a mid-tier QPS load.
Basic targeting and budget pacing only get layered in after the connection to the exchange is locked and stable. Sophisticated features like bid shading or cross-device mapping are useless if the core engine isn’t consistently winning and processing auctions without timing out.
- Connectivity Milestone: Clearing the certification with a few major SSPs to prove your protocol logic is sound.
- Pacing Checks: Verifying the feedback loop shuts down the bidder the second a test budget is hit.
Engineering Roles Required at Each Stage
Building custom DSP software is a specialized engineering feat that requires more than just general web developers. You need low-latency experts who understand memory management and network socket optimization to keep the bidder fast.
As you move into the later stages, data engineers become the priority for managing the massive influx of log-level data and building the reporting pipelines.
A dedicated DevOps lead is essential from day one to manage the global distribution of your bidding clusters.
- Low-Latency Engineer: Focuses on the “hot path” of the bidder, optimizing the C++ or Go code to minimize CPU cycles per request.
- Ad Ops Architect: Translates complex media buying requirements into technical specs for the development team.
Engineering Roles (Team Composition)
| Phase | Primary Role | Core Focus |
|---|---|---|
| MVP | Low-Latency Developer | Protocol handshake & core bidder. |
| Testing | DevOps / SRE | Regional clustering & load balancing. |
| Scaling | Data Engineer | Pipeline efficiency & Kafka streams. |
| Post-Launch | AdOps Architect | Feature roadmap & SSP relations. |
Managing Migration and Parallel-Run Phases
The final stage of custom DSP development involves running your new stack in parallel with your existing commercial seats to benchmark performance. You shouldn’t cut over your entire spend at once; instead, route a small percentage of traffic to the custom bidder to compare win rates and clearing prices.
This “dual-track” period allows you to find discrepancies in how your custom logic interprets data signals versus the legacy platform. Discrepancies in tracking pixels or attribution are usually found and fixed during these high-pressure test weeks.
- Traffic Shifting: Gradually increasing the QPS sent to your custom seat while monitoring for any spikes in exchange-side error rates.
- Audit Reconciliation: Comparing the log-level data from your custom bidder against the billing reports from the SSP to ensure every dollar is accounted for.
Cost Components Involved in Building a DSP Platform
Estimating the price of a build requires a realistic data tiering strategy to keep your cloud bill from exploding. You aren’t just paying for the initial code; you are funding a high-frequency trading environment where every petabyte of log data has a literal storage price.
Most teams underestimate the networking costs associated with ingesting millions of bid requests per second across different global regions. The budget needs to account for the constant “keep-alive” costs of your bidding clusters even when you aren’t winning auctions. You are essentially paying for the right to listen to the market.
Infrastructure Costs Across Compute, Storage, and Networking
The biggest chunk of your cloud infrastructure costs usually comes from networking egress and cross-region data transfers. If your bidder in Europe needs to talk to a database in the US, the latency and the data transfer fees will gut your margins.
You have to balance the high cost of RAM-heavy instances for your bidder with cheaper, slower storage for your historical performance logs. Computing power is a commodity, but the network throughput required for a DSP is a specialized, expensive tier of service.
- Network Throughput: Paying for the dedicated pipes needed to handle sustained, high-volume UDP or TCP traffic from multiple SSPs.
- Memory-Intensive Nodes: Financing the expensive high-RAM instances required to keep your entire user graph in the “hot path” for instant lookup.
Estimating the Cloud Bill for Real-Time Systems
Estimating a DSP development cost in 2026 involves projecting your QPS and mapping that directly to your instance requirements. For a target of 500,000 auctions per second, the server fleet has to sustain that massive ingest without red-lining the CPU or memory.
Many firms realize too late that the “hidden” fees for managed NAT gateways and load balancer processing can actually match the price of the raw compute itself. Burning through a six-figure monthly spend is remarkably easy if the ingestion code isn’t stripped down for maximum resource efficiency.
- Elastic Scaling Buffers: Keeping a margin of idle server capacity to absorb sudden traffic spikes during major shopping holidays.
- Log Aggregation Fees: The high cost of indexing billions of auction signals in third-party observability platforms.
Exchange Certifications, Integrations, and Maintenance Costs
The maintenance cost of custom AdTech platforms often surprises teams who think the work ends at launch. Every time an exchange like Google or Magnite updates their OpenRTB schema, your engineers have to drop everything to update your adapters.
You also have to factor in the annual or per-seat certification fees that some supply partners charge just to keep your bidding pipe open. Ongoing engineering hours are required just to keep the status quo, even if you aren’t adding a single new feature to the UI.
- Protocol Drift: The labor cost of constantly patching your bidder to remain compliant with evolving IAB standards and exchange-specific extensions.
- Partner API Fees: Direct costs for accessing premium inventory discovery tools or specialized data enrichment APIs from SSP partners.
Comparing Build Tax vs Tech Tax Over Time
Evaluating the total cost of ownership for a custom DSP is a battle between the “tech tax” of a vendor and the “build tax” of your own team. While you might eliminate the 15% platform commission, you are replacing it with a fixed payroll of specialized engineers and a massive, unyielding cloud bill.
This math only starts to work in your favor once your media spend hits a threshold where the vendor’s percentage-based fee is significantly higher than your monthly operational overhead. Owning the stack gives you control, but it also means you are solely responsible for the financial impact of any technical downtime.
- Engineering Payroll: The long-term cost of retaining a specialized DevOps and low-latency dev team to prevent system rot.
- Opportunity Cost: Weighing the value of your engineers building a proprietary bidder versus focusing on your core business products.
Total Cost of Ownership (Build vs. Tech Tax)
| Expense Category | Tech Tax (SaaS/Vendor) | Build Tax (Custom Stack) |
|---|---|---|
| Media Margin | 10% – 20% commission fee. | 0% (Total margin recovery). |
| Compute Cost | Included in fee. | Direct cloud bill (AWS/GCP). |
| Engineering | $0 (Vendor maintained). | High (Dedicated internal team). |
| Flexibility | Limited by vendor roadmap. | Unlimited (Build what you need). |
Ongoing Maintenance, Upgrades, and Operational Overhead
Once the custom stack is launched, the real and constant battle against the rate of information transfer begins. entropy. You have to monitor P99 latency benchmarks across every regional pod to ensure that a minor code update or a sudden shift in exchange traffic hasn’t pushed your response times into the danger zone.
Unlike standard SaaS, you are the one responsible for the literal health of the network sockets and the memory management of the bidding nodes. Infrastructure rot happens fast if you aren’t constantly patching the underlying OS and the container orchestration layers. You are essentially maintaining a living system that requires 24/7 oversight to remain competitive in the auction.
Authentication, Authorization, and Access Control Surfaces
A privacy-first AdTech stack depends on physically separating the bidding nodes from the management dashboards. You cannot use a single credential set for both the auction engine and the financial databases. Use short-lived tokens and service-level auth to ensure a breach in one regional cluster doesn’t compromise the whole global setup.
Unshielded internal APIs are a massive risk. An attacker can pivot from a compromised management tool to drain budgets or manipulate bid prices if the access layers aren’t segmented.
- Hard-Coded Scopes: Limiting service accounts to only fetch targeting configs or push logs.
- Network Moats: Placing the bidder in a segmented zone far from the databases holding sensitive audience identifiers.
Platform Evolution as Protocols and Privacy Rules Change
The technical challenge doesn’t lie in how to build a demand-side platform for CTV and OTT but to keep it relevant to the emerging features and standards of modernizing devices. You have to update your bid parsers every time the IAB releases a new VAST version or when a major streaming hardware provider changes their identifier logic.
Privacy regulations like the evolution of the Global Privacy Platform (GPP) require constant code adjustments to stay legally compliant. The stack you build today will be technically obsolete in eighteen months if you don’t dedicate engineering resources to protocol maintenance.
- Schema Evolution: Manually updating the bidder’s JSON parsers to handle new CTV-specific objects like pod positions or content genres.
- Protocol Adaptation: Staying synced with the latest OpenRTB releases to support newer high-definition creative formats and interactive ad units.
Observability, Debugging, and System Introspection at Scale
Debugging scalable microservices in a live RTB environment is difficult because you can’t pause the stream to find a leak. You need deep system introspection to trace a single bid request through the stack without adding any latency.
Without log-level visibility, finding a “ghost” bug that only hits one exchange in one region is nearly impossible. Standard monitoring fails here; you need custom telemetry reporting on the internal state of the bidder’s math.
- Request Tracing: Assigning unique IDs to every handshake to follow the path from the exchange to the final data write.
- Introspection Pipelines: Sampling a small percentage of raw requests to catch malformed payloads or logic errors in the background.
Common Challenges Faced During Custom DSP Development
Building a custom bidder means preparing for “bid storms” where a single misconfigured exchange pipe floods your cluster with millions of invalid requests. If your bid storm mitigation logic isn’t baked into the networking layer, these spikes will overwhelm your CPU and crash your entire regional pod before your auto-scaling can even react.
You have to design for the worst-case traffic scenario as your baseline. Engineering risk often centers on the synchronization of state across disparate data centers. Keeping budget pacing accurate while thousands of nodes are buying simultaneously is a massive technical hurdle.
Managing Bid Storms and Traffic Spikes
A scalable DSP architecture for high-volume RTB needs circuit breakers that trip the moment an exchange exceeds its agreed-upon QPS. Without these, a sudden burst of traffic, whether from a seasonal event or a technical glitch, will cause a cascade of timeouts that makes your bidder invisible to the market.
You need to drop junk traffic at the edge to keep your core processing threads free for legitimate auctions.
- Edge Filtering: Dropping non-compliant or excessive requests at the load balancer level before they reach the bidder logic.
- QPS Shaving: Implementing aggressive rate-limiting that scales down incoming traffic when internal latency hits a specific threshold.
Preventing Partial Failures from Becoming System-Wide Outages
Errors in your exchange adapter logic shouldn’t be allowed to poison the rest of your bidding stack. If one SSP updates its schema and breaks your parser, that specific connection should fail silently and isolate itself without crashing the core engine.
You have to build the bidder with a “fail-fast” mentality where faulty components are automatically bypassed to protect the health of the broader cluster. Isolating these regional or partner-specific hiccups is the difference between a minor dip in win rates and a total platform blackout.
- Adapter Sandboxing: Running exchange-specific code in isolated threads or containers so a crash doesn’t bleed into the main bidder.
- Health Check Probes: Using automated probes to instantly disconnect an exchange pipe if the error rate from that specific adapter spikes.
Enforcing Global Privacy Compliance at the Protocol Level
When calculating the cost to build a custom DSP from scratch in 2026, teams often forget the engineering hours needed for protocol-level privacy enforcement. You have to code the bidder to interpret and act on various consent strings like GPP or TCF v2.2 in under 5 milliseconds.
If your system cannot prove it respected an “opt-out” signal at the moment of the auction, you face massive legal liability. This isn’t just a database setting; it’s a core logic branch that must be checked for every single bid request.
- Consent String Parsers: Highly optimized libraries that extract user rights from the OpenRTB payload without adding processing lag.
- Regional Data Sharding: Physically keeping user profiles in their country of origin to satisfy strict data residency and sovereignty laws.
How Tuvoc Builds and Delivers Custom DSP Platforms
The roadmap for how to build a DSP with Tuvoc centers on a modular engineering approach that prioritizes the core bidding engine before layering on the management UI. We treat the build as a high-frequency trading project, focusing on the stability of the RTB handshake and the efficiency of the data ingestion pipelines.
This ensures the foundation can handle massive QPS loads without the technical debt that usually plagues generic platforms. The delivery process moves through distinct phases of protocol certification and live traffic stress-testing. Custom DSP development at this scale requires a relentless focus on minimizing the path between the auction signal and the bid decision.
Delivery Methodology for High-Load Programmatic Systems
Delivery begins by setting up a load balancing logic that prevents any single bidding node from bottlenecking during a traffic surge. We deploy regional clusters that operate as independent pods, ensuring a latency spike in one geography doesn’t cause a cascade of timeouts globally.
The system is configured to drop non-compliant requests at the edge to keep core compute threads free for actual auctions. By the “penny-buying” phase, the infrastructure has already been stress-tested against simulated bid storms.
- Pod Isolation: Setting up independent regional clusters so maintenance or failure in one zone never stops global bidding.
- Edge Scrubbing: Using filters to remove malformed OpenRTB payloads before they hit the bidder memory.
Aligning Engineering Execution with Long-Term Platform Goals
Successful supply-side platforms (SSP) integration requires a deep understanding of each partner’s specific protocol extensions and certification quirks. We build custom adapters that map unique exchange signals, like video pod positions or proprietary safety scores, directly into your bidder’s decisioning logic.
This alignment ensures your engineering efforts translate into a literal bidding advantage rather than just basic connectivity. The goal is a stack that evolves as your data requirements change, allowing you to inject new proprietary math without rebuilding the entire integration pipe.
- Adapter Modularity: Creating separate, containerized logic for each SSP to simplify updates and prevent partner-specific bugs from spreading.
- Signal Mapping: Translating complex exchange-specific metadata into a unified internal format for the bidding engine to process instantly.
FAQs
For DSP, auction traffic is unimaginably high and therefore, the global servers consume investment. Moreover, building a bidder architecture and acquiring certification for clearance protocol costs somewhere around USD 500,000 or more.
Ownership becomes viable once vendor commission totals exceed the fixed price of running your own private bidding stack and infrastructure.
The stack relies on a low-latency decisioning engine decoupled from persistent storage to handle millions of concurrent OpenRTB requests.
Development moves from a barebones bidding prototype to full exchange certification and regional deployment within a year-long engineering roadmap.
Handling massive QPS volumes requires expensive high-bandwidth pipes and memory-intensive server clusters to maintain the sub-100ms response times exchanges demand.
Manoj Donga
Manoj Donga is the MD at Tuvoc Technologies, with 17+ years of experience in the industry. He has strong expertise in the AdTech industry, handling complex client requirements and delivering successful projects across diverse sectors. Manoj specializes in PHP, React, and HTML development, and supports businesses in developing smart digital solutions that scale as business grows.

Have an Idea? Let’s Shape It!
Kickstart your tech journey with a personalized development guide tailored to your goals.
Discover Your Tech Path →Share with your community!
Latest Articles

Ad Fraud Detection in Programmatic Advertising | Architecture, Techniques & Real-Time Prevention
Why Ad Fraud Persists in Programmatic Ecosystems Fraud is integral to human nature and predates programmatic ecosystems. Neither the fraud…

How to Build an Ad Fraud Detection System: Features, AI Models & Implementation Guide
Defining Requirements for an Ad Fraud Detection System How to build an ad fraud detection system that holds up in…

Future of Real-Time Bidding: Privacy, AI & Cookieless Programmatic
Key Takeaways: The traditional latency-based ad structure has given way to client-side control and on-device logic execution. Identity resolution models…
